转自这里
1. BM(Boyer-Moore)算法
- 思想:有模式串中不存在的字符,那么肯定不匹配,往后多移动几位,提高效率

- BM原理:坏字符规则,好后缀规则
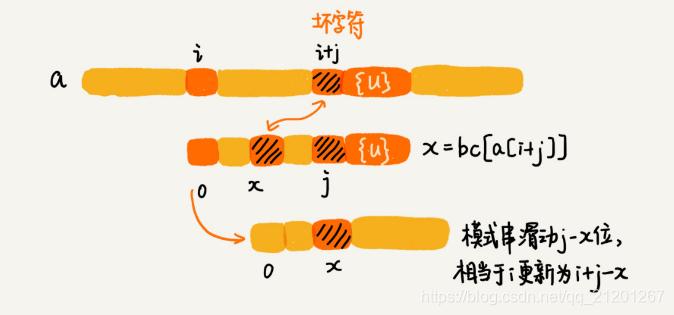
1.1 坏字符规则
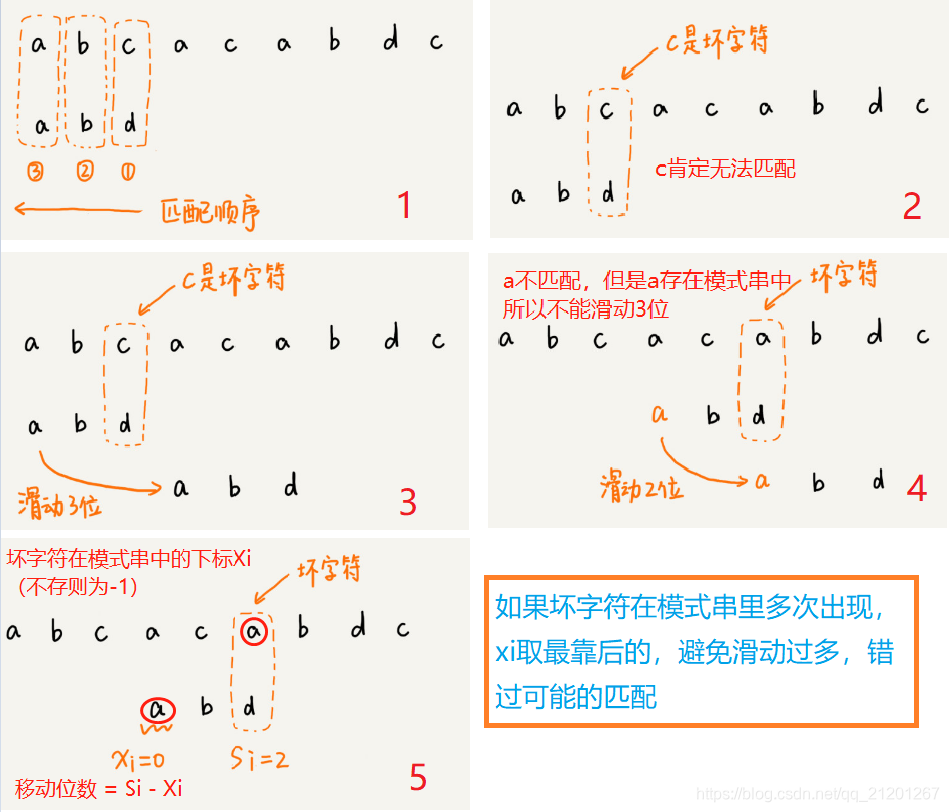
- 利用坏字符规则,BM算法在最好情况下的时间复杂度非常低,是O(n/m)。比如,主串是aaabaaabaaabaaab,模式串是aaaa。每次比对,模式串都可以直接后移四位,所以,匹配具有类似特点的模式串和主串的时候,BM算法非常高效。
- 单纯使用坏字符规则还是不够的。因为根据 si-xi计算出来的移动位数,有可能是负数,比如主串是aaaaaaaaaaaaaaaa,模式串是baaa。不但不会向后滑动模式串,还有可能倒退。所以,BM算法还需要用到“好后缀规则”。
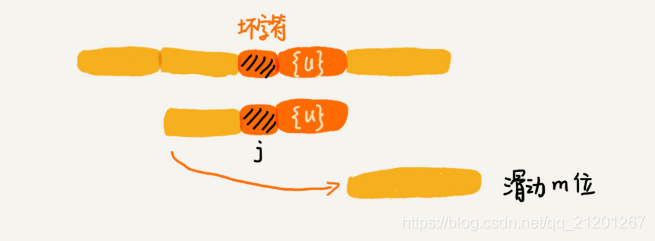
1.2 好后缀规则
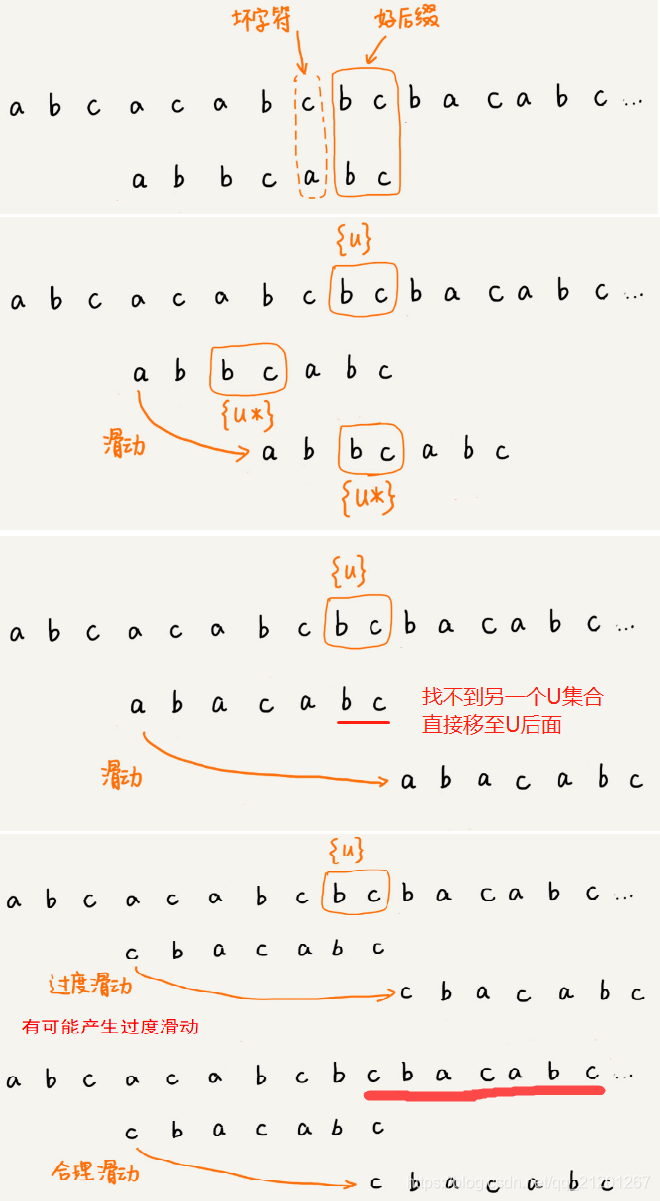
从好后缀的后缀子串中,找一个最长的且和模式串的前缀子串匹配的 {v},滑动至 {v} 对齐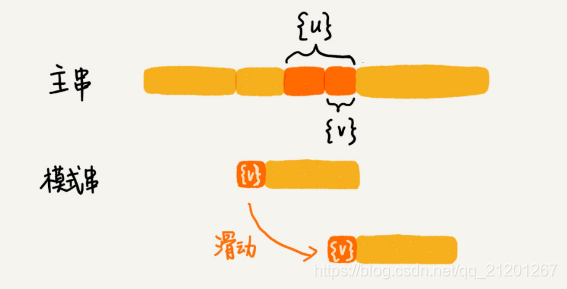
1.3 两种规则如何选择
- 分别计算好后缀和坏字符规则往后滑动的位数,取大的,作为滑动位数(还可以避免负数)
2. BM算法代码实现
2.1 坏字符
- 找到坏字符在模式串中的位置(有重复的,则是靠后的那个)
采用哈希,而不是遍历。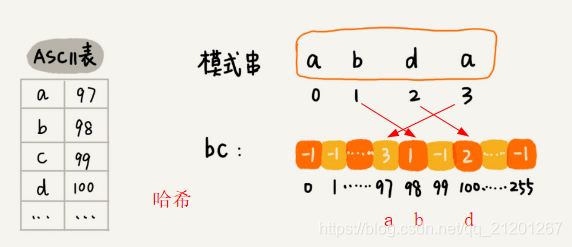
1 |
|
1 | int str_bm(char *a, int n, char *b, int m) |
2.2 好后缀
- 在模式串中,查找跟好后缀匹配的另一个子串
- 在好后缀的后缀子串中,查找最长的、能跟模式串前缀子串匹配的后缀子串
不考虑效率的话,上面两个操作都可以暴力查找;
解决办法: 预先对模式串进行处理。

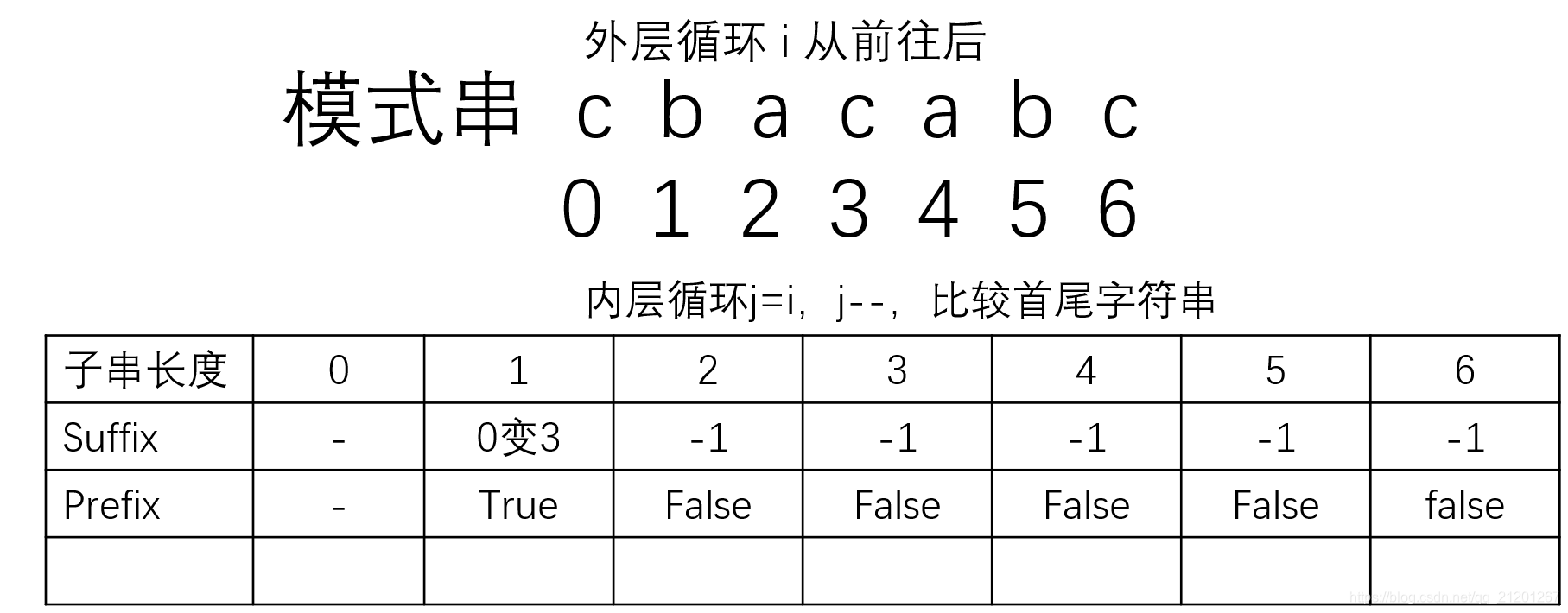
实现过程: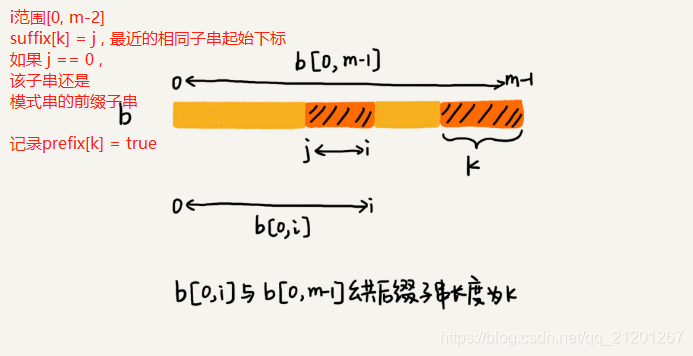
预处理模式串,填充suffix,prefix
1 | void generateGS(char *b, int m, int *suffix, bool *prefix) |
计算滑动位数
- case1:
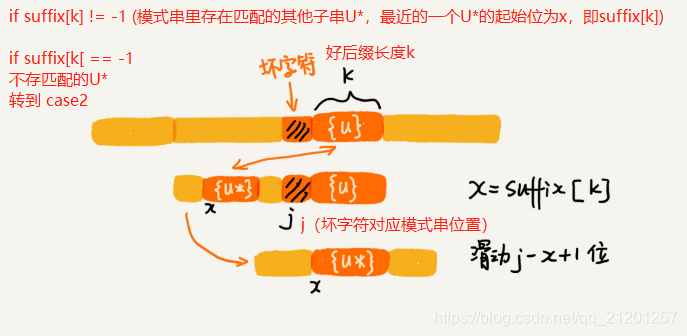
- case2:
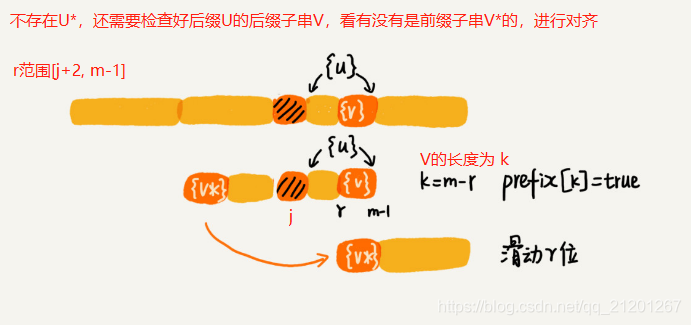
- case3:(以上都不成立,移动整个模式串(长度m))
2.3 完整代码
1 | /** |

2.4 调试
为方便调试,将字符集SIZE改为3,ascii = int(b[i]-'a')
- 坏字符在模式串中的位置(靠后的那个)
badchar[0]:a是4
badchar[1]:b是5
badchar[2]:c是6 - 预处理模式串
- 按规则移动




3. 总结
- BM算法的内存消耗
整个算法用到了额外的3个数组,其中bc数组的大小跟字符集大小有关,suffix数组和prefix数组的大小跟模式串长度m有关。
如果处理字符集很大的字符串匹配问题,badchar数组对内存的消耗就会比较多。
因为好后缀和坏字符规则是独立的,如果运行的环境对内存要求苛刻,可以只使用好后缀规则,不使用坏字符规则,就可以避免badchar数组过多的内存消耗。不过,单纯使用好后缀规则的BM算法效率就会下降一些了。 - 时间复杂度
以上BM算法是个初级版本。这个版本,在极端情况下,预处理计算suffix数组、prefix数组的性能会比较差。
比如模式串是aaaaaaa这种包含很多重复的字符的模式串,预处理的时间复杂度就是O(m^2)。如何优化这种极端情况下的时间复杂度退化,以后再找空研究。
实际上,BM算法的时间复杂度分析起来是非常复杂,论文“A new proof of the linearity of the Boyer-Moore string searching algorithm”证明了在最坏情况下,BM算法的比较次数上限是5n。论文“Tight bounds on the complexity of the Boyer-
Moore string matching algorithm”证明了在最坏情况下,BM算法的比较次数上限是3n。
- BM算法核心思想是,利用模式串本身的特点,在模式串中某个字符与主串不能匹配的时候,将模式串往后多滑动几位,以此来减少不必要的字符比较,提高匹配的效率。
- BM算法构建的规则有两类,坏字符规则和好后缀规则。
- 好后缀规则可以独立于坏字符规则使用。
- 因为坏字符规则的实现比较耗内存,为了节省内存,我们可以只用好后缀规则来实现BM算法。