【转】种类并查集
拖了一大堆算法 : ( , 行吧,写不过来了~ 直接转一篇大佬写的叭~~
转自这里
并查集的应用很多,今天我们来看一个并查集的拓展——种类并查集。
一般的并查集,维护的是具有连通性、传递性的关系,例如亲戚的亲戚是亲戚。但是,有时候,我们要维护另一种关系:敌人的敌人是朋友。种类并查集就是为了解决这个问题而诞生的。
我们先来看一个例题:
(洛谷P1525 关押罪犯)
题目描述
S 城现有两座监狱,一共关押着 N 名罪犯,编号分别为 1-N。他们之间的关系自然也极不和谐。很多罪犯之间甚至积怨已久,如果客观条件具备则随时可能爆发冲突。我们用“怨气值”(一个正整数值)来表示某两名罪犯之间的仇恨程度,怨气值越大,则这两名罪犯之间的积怨越多。如果两名怨气值为 c 的罪犯被关押在同一监狱,他们俩之间会发生摩擦,并造成影响力为 c 的冲突事件。
每年年末,警察局会将本年内监狱中的所有冲突事件按影响力从大到小排成一个列表,然后上报到 S 城 Z 市长那里。公务繁忙的 Z 市长只会去看列表中的第一个事件的影响力,如果影响很坏,他就会考虑撤换警察局长。
在详细考察了N 名罪犯间的矛盾关系后,警察局长觉得压力巨大。他准备将罪犯们在两座监狱内重新分配,以求产生的冲突事件影响力都较小,从而保住自己的乌纱帽。假设只要处于同一监狱内的某两个罪犯间有仇恨,那么他们一定会在每年的某个时候发生摩擦。
那么,应如何分配罪犯,才能使 Z 市长看到的那个冲突事件的影响力最小?这个最小值是多少?
输入格式
每行中两个数之间用一个空格隔开。第一行为两个正整数 N,M,分别表示罪犯的数目以及存在仇恨的罪犯对数。接下来的 MM 行每行为三个正整数 $a_j,b_j,c_j$,表示 $a_j$ 号和 $b_j$ 号罪犯之间存在仇恨,其怨气值为 $c_j$。数据保证 $1<a_j\leq b_j\leq N$, $0 < c_j\leq 10^9$,且每对罪犯组合只出现一次。
输出格式
共 1 行,为 Z 市长看到的那个冲突事件的影响力。如果本年内监狱中未发生任何冲突事件,请输出 0。
其实很容易想到,这里可以贪心,把所有矛盾关系从大到小排个序,然后尽可能地把矛盾大的犯人关到不同的监狱里,直到不能这么做为止。这看上去可以用并查集维护,但是有一个问题:我们得到的信息,不是哪些人应该在相同的监狱,而是哪些人应该在不同的监狱。这怎么处理呢?这个题其实有很多做法,但这里,我们介绍使用种类并查集的做法。
我们开一个两倍大小的并查集。例如,假如我们要维护4个元素的并查集,我们改为开8个单位的空间:

我们用1~4维护朋友关系(就这道题而言,是指关在同一个监狱的狱友),用5~8维护敌人关系(这道题里是指关在不同监狱的仇人)。现在假如我们得到信息:1和2是敌人,应该怎么办?
我们merge(1, 2+n), merge(1+n, 2);。这里n就等于4,但我写成n这样更清晰。对于1个编号为i的元素,i+n是它的敌人。所以这里的意思就是:1是2的敌人,2是1的敌人。
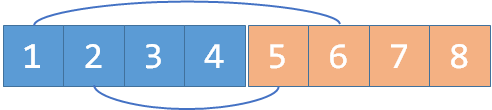
现在假如我们又知道2和4是敌人,我们merge(2, 4+n), merge(2+n, 4);:
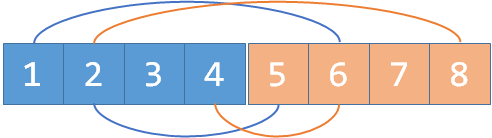
发现了吗,敌人的敌人就是朋友,2和4是敌人,2和1也是敌人,所以这里,1和4通过2+n这个元素间接地连接起来了。这就是种类并查集工作的原理。
代码如下:
1 |
|
刚才我说,种类并查集可以维护敌人的敌人是朋友这样的关系,这种说法不够准确,较为本质地说,种类并查集(包括普通并查集)维护的是一种循环对称的关系。
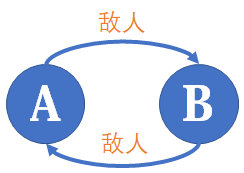
所以如果是三个及以上的集合,只要每个集合都是等价的,且集合间的每个关系都是等价的,就能够用种类并查集进行维护。例如下面这道题:
题目描述
动物王国中有三类动物 A,B,C,这三类动物的食物链构成了有趣的环形。A 吃 B,B 吃 C,C 吃 A。
现有 N 个动物,以 1 - N 编号。每个动物都是 A,B,C 中的一种,但是我们并不知道它到底是哪一种。
有人用两种说法对这 N 个动物所构成的食物链关系进行描述:
- 第一种说法是
1 X Y,表示 X 和 Y 是同类。- 第二种说法是
2 X Y,表示 X 吃 Y 。此人对 N 个动物,用上述两种说法,一句接一句地说出 K 句话,这 K 句话有的是真的,有的是假的。当一句话满足下列三条之一时,这句话就是假话,否则就是真话。
- 当前的话与前面的某些真的话冲突,就是假话
- 当前的话中 X 或 Y 比 N 大,就是假话
- 当前的话表示 X 吃 X,就是假话
你的任务是根据给定的 N 和 K 句话,输出假话的总数。
输入格式
第一行两个整数,N,K,表示有 N 个动物,K 句话。
第二行开始每行一句话(按照题目要求,见样例)
输出格式
一行,一个整数,表示假话的总数。
我们会发现 A、B、C三个种群天然地符合用种类并查集维护的要求。
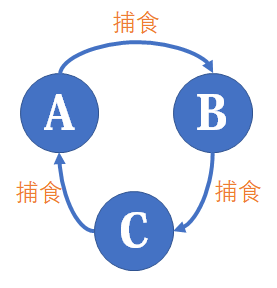
于是我们可以用一个三倍大小的并查集进行维护,用i+n表示i的捕食对象,而i+2n表示i的天敌。
1 |
|