Mysql命令笔记
内容有点多哈,所有内容都写一起了~~
1 mysql管理数据库操作
| 命令说明 | 命令 |
|---|---|
| 创建数据库 | CREATE DATABASE [数据库名]; |
| 查看已有数据库 | SHOW DATABASES; |
| 删除数据库 | DROP DATABASE [数据库名]; |
| 选择数据库 | USE [数据库名]; |
2 mysql数据表操作
2.1 mysql数据类型
列举了一些常用的数据类型,更多类型可以参考这里
| 类型 | 大小 | 范围(有符号) | 范围(无符号) | 说明 |
|---|---|---|---|---|
| INT或INTEGER | 4 bytes | (-2 147 483 648,2 147 483 647) | (0,4 294 967 295) | 大整数值 |
| FLOAT | 4 bytes | (-3.40 E+38,-1.17 E-38),0,(1.17 E-38,3.40 E+38) | 0,(1.17 E-38,3.40 E+38) | 单精度 浮点数值 |
| DOUBLE | 8 bytes | (-1.79 E+308,-2.22 E-308),0,(2.22 E-308,1.79 E+308) | 0,(2.22 E-308,1.79E+308) | 双精度 浮点数值 |
| CHAR | 0-255 bytes | 定长字符串 | ||
| VARCHAR | 0-65535 bytes | 变长字符串 | ||
| DATE | 3 bytes | 1000-01-01/9999-12-31 | 日期值 |
注:char(n)表示varchar(n)代表n个字符,并不代表字节个数,如char(30)就能存储30个字符(其中char最多只能存储256字节大小的字符)
2.2 创建数据表
创建数据表的通用语法如下:
1 | CREATE TABLE table_name (column_name column_type); |
举个栗子(栗子采自菜鸟教程):
1 | CREATE TABLE IF NOT EXISTS `runoob_tbl`( |
实例解析:
- 如果你不想字段为 NULL 可以设置字段的属性为 NOT NULL, 在操作数据库时如果输入该字段的数据为NULL ,就会报错。
- AUTO_INCREMENT定义列为自增的属性,一般用于主键,数值会自动加1。
- PRIMARY KEY关键字用于定义列为主键。 您可以使用多列来定义主键,列间以逗号分隔。
- ENGINE 设置存储引擎,CHARSET 设置编码。
设置属性常用的关键字:
1 | 1. NOT NULL:字段不能为NULL,否则报错 |
2.3 数据表索引
当表中的数据量比较大时,查询操作会比较耗时,建立索引是加快查询的有效手段,用户可以根据应用环境在基本表上建立一个或者多个索引,以提供多种存区路径,加快查找速度。
数据库索引有多种类型:
- 顺序文件上的索引:按指定属性值升序或者降序存储的,在该属性上建立一个顺序索引文件,索引文件由属性值和相应的元组指针组成,查找时就能使用二分查找了。
- B+树索引:B+树索引是将索引属性组织成B+树形式,B+树的叶结点为属性值和相应的元组指针。B+树索引具有动态平衡的优点。
- 散列索引是建立若干个桶,将索引属性按照其散列函数值映射到相应桶中,桶中存放索引属性值和相应的元组指针。散列索引具有查找速度快的特点。
- 位图索引是用位向量记录索引属性中可能出现的值,每个位向量对应一一个可能值。
建立索引的通用语句:
1 | CREATE [UNIQUE] [CLUSTER] INDEX <索引名> ON <表名>(<列名> <次序>, ...); |
说明几点:
- UNIQUE:表示创建唯一所引(索引值唯一);
- CLUSTER:表示建立聚簇索引(聚簇索引的顺序就是数据的物理存储顺序,而对非聚簇索引的顺序存储其元组指针,所以一个表只能有一个聚簇索引,具体可以看看这篇博客);
- 次序:有降序DESC和升序ASC两种。
- 字符串列可以指定长度:格式为<列名>(长度) <次序>
修改索引:
1 | ALTER TABLE <表名> RENAME INDEX <旧索引名> TO <新索引名>; |
删除索引:
1 | DROP INDEX <索引名> ON <表名>; |
2.4 重命名数据表
通用语法:
1 | RENAME TABLE [旧表名] to [新表名]; |
2.5 删除数据表
通用语法:
1 | DROP TABLE table_name ; |
举个栗子(栗子采自菜鸟教程):
1 | root@host# mysql -u root -p |
2.6 查看数据库中的数据表
查看有哪些数据表
1 | SHOW TABLES; |
查看数据表状态
1 | SHOW TABLE STATUS FROM [数据库名] |
2.7 查看数据表
查看数据表的属性,属性类型,主键信息 ,是否为 NULL,默认值等其他信息。
1 | SHOW COLUMNS FROM [数据表名] |
查看数据表的详细索引信息,包括PRIMARY KEY(主键)
1 | SHOW INDEX FROM [数据表名] |
3 mysql数据表增删查改操作
以下是一些命令的汇总
| 命令说明 | 命令 |
|---|---|
| 插入数据 | INSERT INTO <表名>(<属性列1>, <属性列2>,…) VALUES(<常量1>, <常量2>,…) |
| 查询数据 | SELECT [ALL|DISTINCT] <目标列表达式>… FROM <表名或视图名> [WHERE <条件表达式>] [GROUP BY <列名 1> [HAVING <条件表达式>]] [ORDER BY <列名 2> [ASC|DESC]] |
| 修改数据 | UPDATE <表名> SET <列名>=<表达式>,… [WHERE <条件>] |
| 删除数据 | DELETE FROM <表名> [WHERE <条件>…] |
关于上表的一些说明:
- 尖括号
<>括起来的通常是一些表名或者列名等等 - 方括号
[]表示可选项 - 还有一些关键字的说明,ALL(默认):选择全部,DISTINCT:去除重复数据,ASC(默认):递增,DESC:递减
这一部分主要时mysql上述命令的一些练习~
这里的练习是采用《数据库系统概论(王珊 萨师煊)》课本上的例题~
这里主要涉及三个表:
学生表:Student(Sno, Sname, Ssex, Sdept) (学号,姓名,性别,院系)
| Sno | Sname | Ssex | Sage | Sdept |
|---|---|---|---|---|
| 201215121 | 李勇 | 男 | 20 | CS |
| 201215122 | 刘晨 | 女 | 19 | CS |
| 201215123 | 王敏 | 女 | 18 | MA |
| 201215125 | 张立 | 男 | 19 | IS |
课程表:Course(Cno, Cname, Cpno, Ccredit) (课程号,课程名,先行课,学分)
| Cno | Cname | Cpno | Ccredit |
|---|---|---|---|
| 1 | 数据库 | 5 | 4 |
| 2 | 数学 | 2 | |
| 3 | 信息系统 | 1 | 4 |
| 4 | 操作系统 | 6 | 3 |
| 5 | 数据结构 | 7 | 4 |
| 6 | 数据处理 | 2 | |
| 7 | PASCAL语言 | 6 | 4 |
学生选课表:SC(Sno, Cno, Grade) (学号,课程号,成绩)
| Sno | Cno | Grade |
|---|---|---|
| 201215121 | 1 | 92 |
| 201215121 | 2 | 85 |
| 201215121 | 3 | 88 |
| 201215122 | 2 | 90 |
| 201215122 | 3 | 80 |
3.1 单表查询
3.1.1 简单查询
首先简单的查询几列
1 | select Sno Sname |
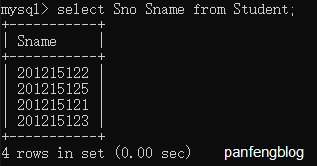
使用*可以选择全体列
1 | select * |
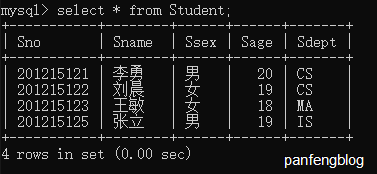
3.1.2 目标表达式
我们的select语句后接<目标表达式>,<目标表达式>主要包括算数表达式、字符串常量、函数等等,可以参考下面这个栗子(目标表达式后跟的是别名):
1 | select Sname,'This is a string' String, 2020-Sage BirthYear, lower(Sdept) Sdept |
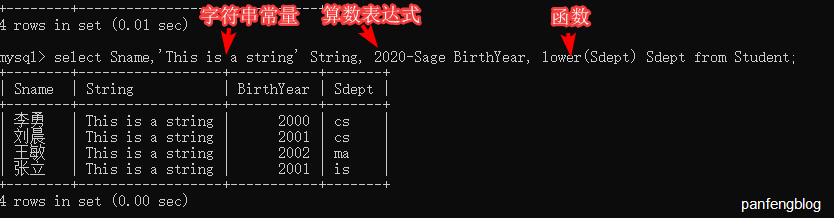
3.1.3 去重
去重非常简单,加上DISTINCT就可以了
1 | select distinct Sno |
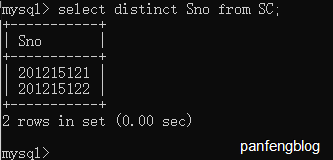
3.1.4 查询满足条件的元组
我们使用where子句来查询我们所需要的元组,常用的查询条件如下表所示(摘自《数据库系统概论(王珊 萨师煊)》):
| 查询条件 | 谓词 |
|---|---|
| 比较大小 | =, >, <, >=, <=, !=, <>, !>, !<, 以及NOT加上述运算符 |
| 确定范围 | BETWEEN AND, NOT BETEWEEN AND |
| 确定集合 | IN, NOT IN |
| 字符匹配 | LIKE, NOT LIKE |
| 空值 | IS NULL, IS NOT NULL |
| 逻辑运算 | AND, OR, NOT |
接下来一一尝试以下上面的这些查询条件
- 比较大小
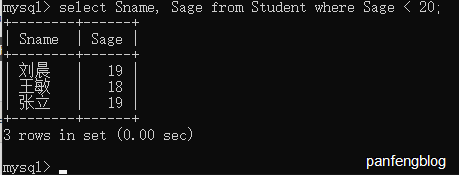
这个很好理解,比如说查询20岁以下的同学的姓名和年龄(其他的就不一一介绍了,比较运算符很好理解)
1 | select Sname, Sage |
- 确定范围
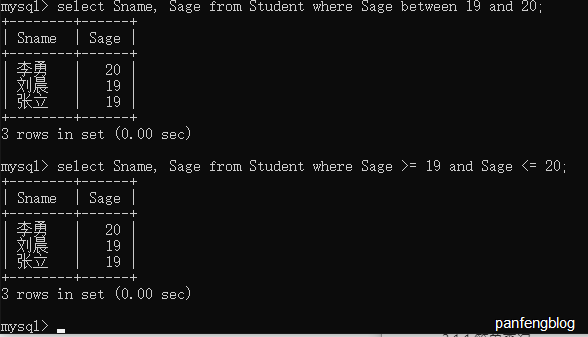
乍一看可能会有点懵,其实很简单,比如说查询年龄在19~20岁的同学(注意是闭区间!包括19和20)
并且between and其实可以用上述的比较大小运算符轻松代替的~
1 | select Sname, Sage |
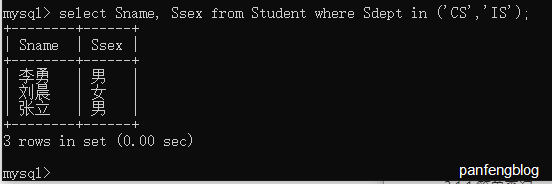
- 确定集合
使用IN可以查找属于指定集合的元组,如下
1 | select Sname, Ssex |
- 字符匹配
使用LIKE来进行字符串的匹配,通用语法如下:
1 | [NOT] LIKE '<匹配串>' [ESCAPE '<换码字符>'] |
我们通常使用两个通配符:
%:表示任意长度的字符串(包括长度为0),比如’a%b’就能匹配以a开头以b结尾的任意字符串,比如’askdhb’_:表示单个任意字符,比如’a_b’可以匹配’axb’
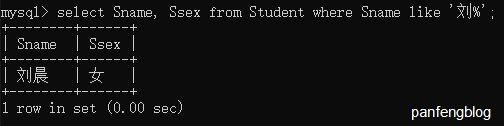
比如我们查询姓刘的同学:
1 | select Sname, Ssex |
当我们需要查询%和_字符本身时,我们就需要转义字符,mysql默认的转义字符为\,使用\%和\_匹配,当然我们也可以匹配一些不可以见字符,比如:\0: 一个ASCII 0 (NUL)字符; \n:一个新行符; \t:一个定位符; \r一个回车符; \b一个退格符; \'一个单引号(“’”)符; \"一个双引号符; \\一个反斜线(“\”)符。
我们也可以使用ESCAPE更改转义字符,比如我们使用$作为转义字符,这样我们就能使用$%匹配$_了。
1 | select Cno, Ccredit |

3.1.5 排序
当我们需要让我们查询的结果进行排序显示时,我们就可以使用ORDER BY子句,升序为ASC,降序为DESC。
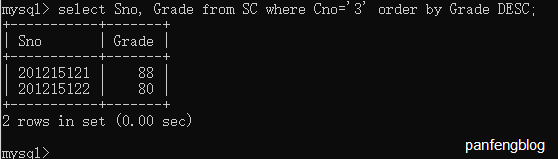
比如说我们查询3号课程的成绩,并且按照降序显示:
1 | select Sno, Grade |
3.1.6 聚集函数
sql提供了许多聚集函数,如下表
| 聚集函数 | 说明 |
|---|---|
| COUNT(*) | 统计元组的个数 |
| COUNT([DISTINCT|ALL] <列名>) | 统计一列中值的个数 |
| SUM([DISTINCT|ALL] <列名>) | 计算一列值的总和 |
| AVG([DISTINCT|ALL] <列名>) | 计算一列值的平均值 |
| MAX([DISTINCT|ALL] <列名>) | 计算一列值的最大值 |
| MIN([DISTINCT|ALL] <列名>) | 计算一列值的最小值 |
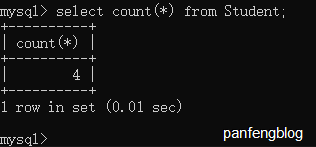
简单尝试一下,比如查询一下学生的总人数:
1 | select count(*) |
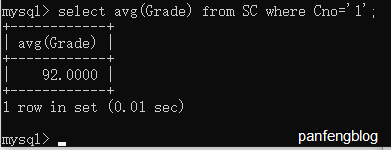
计算1号课程同学们的平均成绩:
1 | select avg(Grade) |
3.1.7 分组
分组常常和聚集函数同时使用,使用分组可以细化聚集函数的作用对象,分组后聚集函数将作用于每一组,每一组都得到一个函数值。
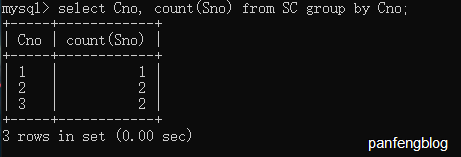
比如说计算各个课程的选课的学生个数:,
1 | select Cno, count(Sno) |
当然分组后可能还需要对组进行一些筛选,此时不能使用WHERE子句,需要使用HAVING子句,where作用与表或视图,选取出元组,而having作用于组,选择出符合条件的组。
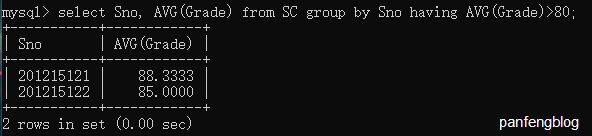
比如查询平均成绩大于80的同学:
1 | select Sno, AVG(Grade) |
3.2 多表查询
3.2.1 等值连接与非等值连接
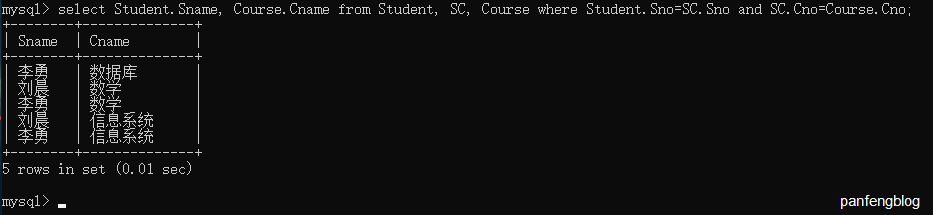
其实和单表查询差不多,比如说我们查询每个同学选修课程的情况(每个同学名字在Student表中,而课程名在Course表中,而这两个表又没有任何关系,我们需要第三个表SC来连接这两个表)
1 | select Student.Sname, Course.Cname |
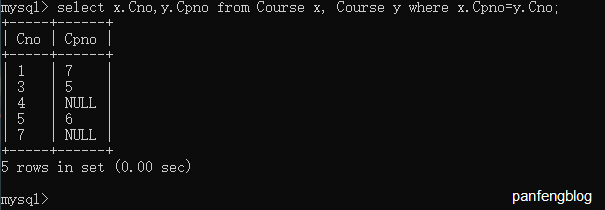
有时我们可能需要一个表和自身连接,这时我们只需要给这个表起个别名就可以了(在表明后加as再更别名即可,当然as可以省略),和普通的多表查询没用区别。
比如说我们现在需要查询一门课程的间接先修课程(先修课程的先修课程)
1 | select x.Cno,y.Cpno |
3.2.2 外连接
外连接需要使到JOIN,通用语句如下:
1 | SELECT [ALL|DISTINCT] <目标列表达式>... |
JOIN有三种模式,INNER(内连接),LEFT(左外连接),RIGHT(右外连接),JOIN默认为内连接(就是上文提到的等值连接与非等值连接)
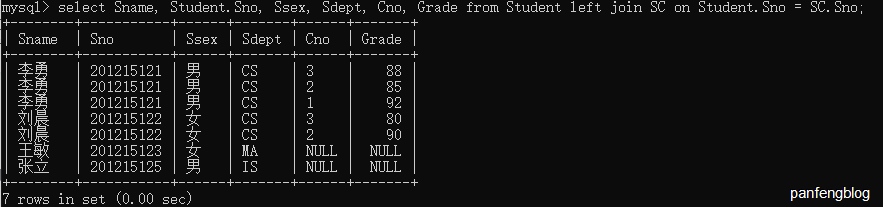
举个栗子,我们需要查询所有同学的基本信息以及选课信息:
1 | select Sname, Student.Sno, Ssex, Sdept, Cno, Grade |
3.4 嵌套查询
一个SELECT-FROM-WHERE语句称为一个查询块,将一个查询块嵌套在另一个查询块的WHERE子句或HAVING短语的条件中的查询称为嵌套查询。
3.4.1 不相关子查询
子查询结果的查询条件与不依赖于父查询,这类子查询称为不相关子查询。
举个栗子,查询选修了2号课程的同学名字
1 | select Sname |
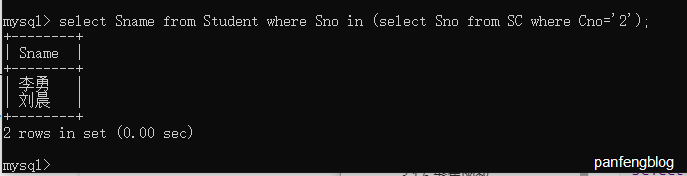
当然,许多嵌套查询都能转化为多表查询的!
嵌套查询也可以嵌套再from子句中。
比如下面这个栗子,计算 $\prod_{SC}^{}(SC)\times Student$
1 | select * |
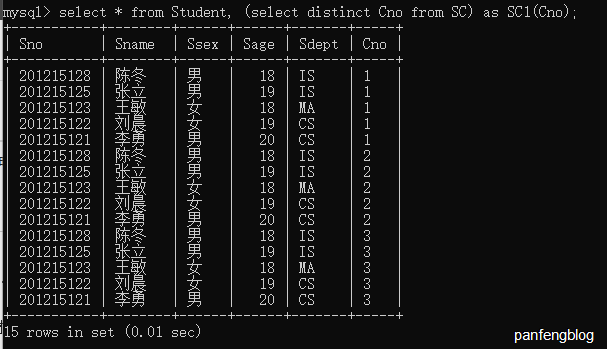
3.4.2 相关子查询
当我们的查询的查询条件依赖于父查询,这类子查询就称为相关子查询。
比如说我们查询出每个同学成绩超过其平均成绩的课程信息和学生信息,就能用到相关子查询。
1 | select x.Sno, x.Cno |
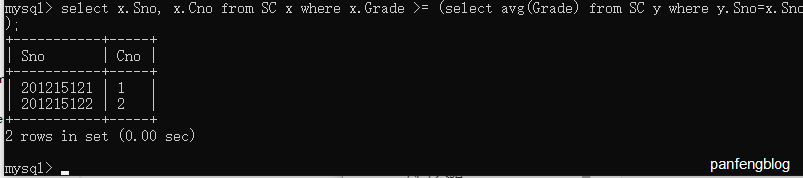
3.4.3 关于ANY(SOME)和ALL谓词
简单解释一下两个谓词:
- ANY(SOME):有一个条件为真,则为真,反之为假
- ALL:全部条件为真,则为真,反之为假
其实非常好理解,看个简单的栗子。查询非CS系中比CS系中任意一个同学年龄小的学生姓名和年龄。(使用any或some都可以)
1 | select Sname, Sage |
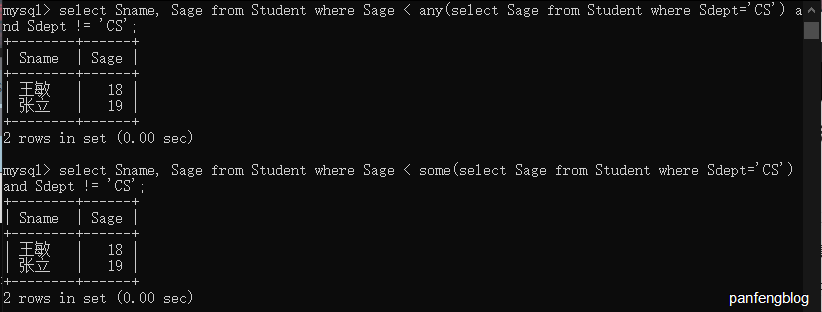
查询非CS系中比CS系中所有同学年龄都小的学生姓名和年龄。此时我们就使用ALL。
1 | select Sname, Sage |

3.4.4 关于EXISTS谓词
一些带EXISTS或NOT EXISTS谓词的子查询不能被其他形式的子查询等价替换,并且由于EXISTS并不关心内层查询的具体值,因此其效率不一定低于不相关子查询,有时是高效的方法
EXISTS代表存在量词 $\exists$ ,如果集合为空,返回false,否则返回true。EXISTS配合使用NOT可以实现一些全称量词 $\forall$ 的表述。
查询选修了1号课程的学生姓名。
1 | select Sname |

举个更复杂的栗子,查询选修了全部课程的学生姓名。
我们设事件$P$为学生选修了该课程,设$x$为课程,于是我们需要求满足 $\forall x \; P$ 的学生,可以等价变形为 $\neg (\exists x \;(\neg P))$,于是我们就能写出查询语句了~
1 | select Sname |

3.5 集合查询
MySql只支持Union(并集)集合运算,但是对于交集Intersect、差集Except,就没有实现了,可以通过其他的一些运算模拟实现 : )
3.6 插入数据
3.6.1 插入元组
插入元组的通用格式为:
1 | INSERT |
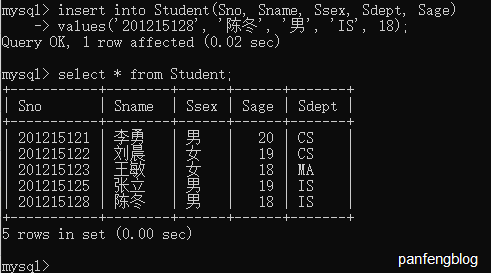
这个命令非常简单,比如说我们插入一个新的学生
1 | insert |
3.6.2 插入子查询结果
我们可以将子查询嵌套子在INSERT语句中用于生成插入的数据。
插入子查询结果的通用语句格式如下:
1 | INSERT |
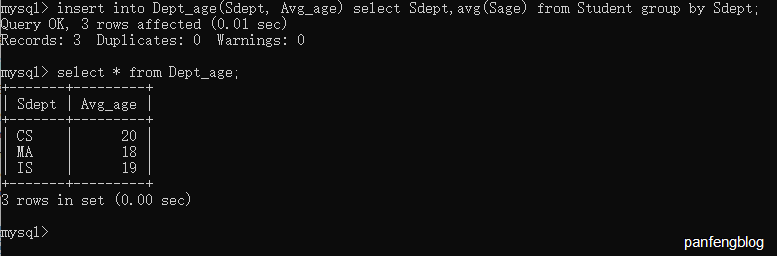
举个栗子,我们将统计各个院系的平均年龄,然后保存在新的数据表中
1 | insert |
3.7 修改数据
修改数据操作非常简单,只需要结合之前的查询操作就能轻松实现修改数据了,下面是修改数据的通用语句:
1 | UPDATE <表名> |
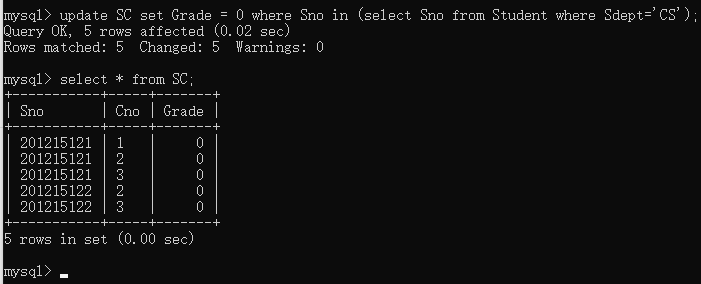
举个栗子,将CS系的同学的分数置为0。
3.8 删除数据
删除数据也比较简单,写好where子句就好了~通用语句格式如下:
1 | DELETE |
举个栗子,比如删除SC表中CS系同学的记录。
1 | delete |

4 视图
视图是一个或几个基本表(或视图)导出的表。它与基本表不同,是一个虚表,数据库中只存放视图的定义,而不存放视图对应的数据,所以一旦基本表数据发生变化,从视图中查询出的数据也就随之改变了。
4.1 建立视图
值得注意的是, 关系数据库系统执行 CREATE VIEW 语句的结果只是把视图的定义存入数据字典,并不执行其中的select语句,只有在对视图进行查询时,才按照视图的定义从基本表中将数据查出。
采用select子句建立视图,通用句型如下:
1 | CREATE VIEW <视图名> [(列名),...] |
说明:WITH CHECK OPTION 表示对视图进行UPDATE、INSERT和DELETE操作时要保证更新、插入或删除的行满足视图定义的谓词条件(即子查询的条件表达式)
举个栗子,建立CS系学生的视图
1 | create view IS_Student |

视图可以建立在已有的视图或者基本表上!
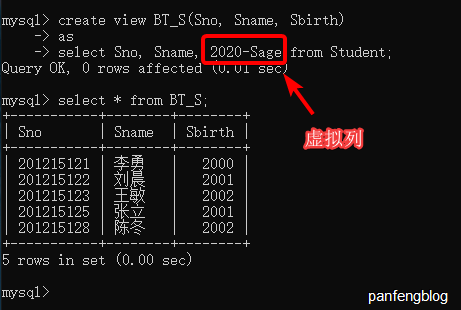
虚拟列:派生属性在基本表中并不实际存在的列。
举个栗子,我们定义一个学生出生年份的视图,其中的Sbirth列就是一个虚拟列,在基本表中是不存在的
1 | create view BT_S(Sno, Sname, Sbirth) |
分组视图:使用聚集函数和 GROUP BY 子句的查询定义视图,这种视图称为分组视图。
举个栗子,将学生的学号及平均成绩定义为一个视图。
1 | create view S_G(Sno, G_avg) |
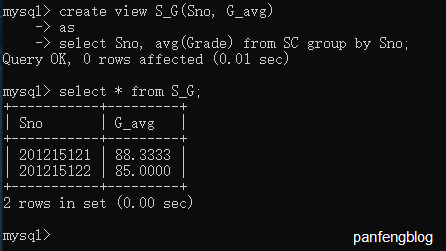
4.2 删除视图
非常简单~下面时通用命令:
1 | DROP VIEW <视图名> [CASCADE] |
说明:使用CASCADE会将该视图及其导出的视图全部删除。
举个栗子,比如删除 S_G 视图

4.3 查询视图
视图定义好了之后查询操作和查询基本表没用任何区别~
但是在视图查询底层实现和基本表查询并不相同,这就涉及到一个视图消解的问题。
视图消解:从数据字典中取出视图的定义,把定义的子查询和用户的查询结合起来,转化成等价的对基本表的查询,然后再执行修正了的查询,这一个转化的过程就称为视图消解。
应该还是比较好理解的(上述定义摘自课本),但是有时这种转化会出现一些错误,这里就不细说了吧(可以参看课本P122)
4.4 更新视图
和查询视图一样,同样有一个转化的过程,所以并不是所有视图都是可以更新的!(当然更新的命令和操作基本表没用区别)