Pandas学习
pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。pandas提供了大量能使我们快速便捷地处理数据的函数和方法。你很快就会发现,它是使Python成为强大而高效的数据分析环境的重要因素之一。(来自百度百科)
这是参考了知乎上这篇文章的教程做的一个笔记https://www.zhihu.com/question/56310477/answer/873227129?utm_source=wechat_session
第一步当时是import pandas as pd
1. 创建、读取和存储
1.1 创建
创建函数包括两个部分,一部分是一个字典,表示各个数据项;另一个是相应的索引
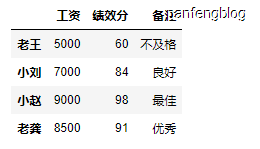
1 | df1 = pd.DataFrame({'工资':[5000, 7000, 9000, 8500], |
创建后的效果:
1.2 读取
这个就没什么好说的,直接看下面函数就行
1 | df = pd.read_csv('csv文件路径', engine = 'python') |
1.3 存储数据
没啥好说的,直接保存就完事了
1 | df.to_csv('csv文件路径') |
2. 数据查看
2.1 查看数据前(后) i 行
有时数据量非常大,查看所有数据没有多大意义,所以只需查看一部分数据了解概括
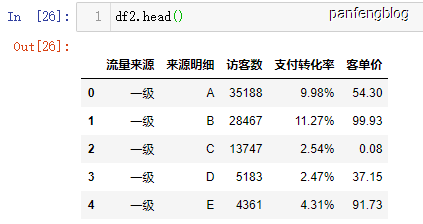
1 | df.head() # 默认查看数据前五行,当时也可指定行数df.head(i) |
查看效果:
2.2 查看数据信息(行数、缺失值等)
将数据加载好了后可以使用info函数查看数据信息
1 | df.info() |
输出结果:

2.3 统计信息
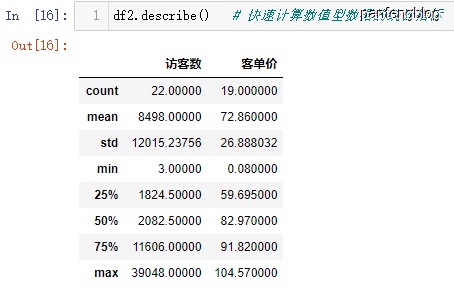
可以对数据中的数值型数据进行统计
1 | df.describe() |
输出样例:
3. 数据列的操作
3.1 增加数据列
和python的字典类似,代码如下
1 | df['新增的列'] = range(0, len(df)) |
输出结果:
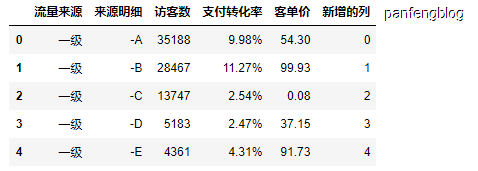
3.2 删除列
使用drop函数
1 | df.drop('新增的列', axis = 1, inplace = True) # 删除数据,axis=1表示对列进行操作, inplace表示在源数据上进行修改 |
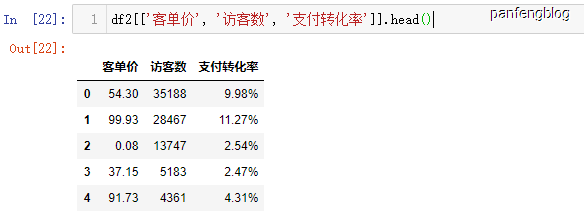
3.3 选中列
同时选中多个列
1 | df2[['列名1', '列名2', '列名3']] |
举个栗子:
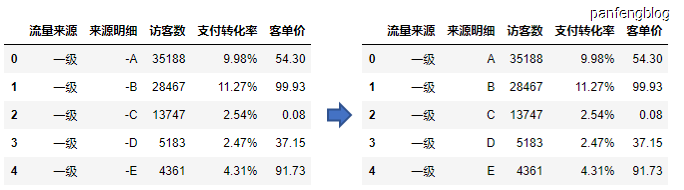
4. 数据类型
4.1 字符串
值得注意的是,保存的数据中除了数值型数据,其他类型数据都是object,所以对数据的字符串进行处理需要先调用str,其余操作与python完全相同
举个栗子:
1 | df2['来源明细'] = df2['来源明细'].str.replace('-','') |
输出结果:
4.2 数值型
这个其实没啥好讲的,可以直接对数据进行操作,不过值得注意的是,可以使用其广播特性,可以看下面这个栗子:
1 | df['访客数']+1000 # 广播机制,为这一列都加上1000 |
4.3 时间类型
时间类型里面学问比较多,这里简要学习一下
首先添加时间:
1 | data = [] |
输出效果:
可以看到默认添加的时间是字符串类型的,但是可以将字符串类型的转化为时间类型(当然需要满足xxxx-xx-xx或xxxx/xx/xx等格式)
1 | df2['日期'] = pd.to_datetime(df2['日期']) |
输出效果:
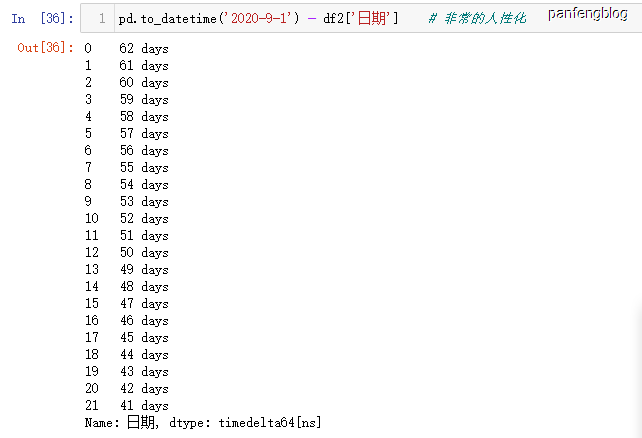
当我们将数据转化为时间类型时,就行进行许多人性化的操作,比如减法(求距离某一天有多少天)
5. 灵活的索引
5.1 位置索引
位置索引使用iloc函数,使用起来比较简单,可以直接看下面代码。
1 | df.iloc[13:18, 0:4] # 第个参数填写选取行,第二个参数填写选取列 |
选取效果:
5.2 标签索引
和位置索引类似,使用loc函数,使用方法类似,但是由于使用的不是数字,而是标签,所以填写参数的形式有所不同。
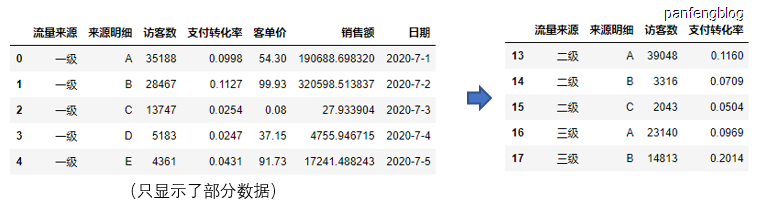
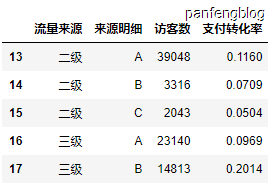
1 | df2.loc[df2['流量来源'].isin(['二级', '三级']), ['流量来源', '来源明细', '访客数', '支付转化率']] |
输出结果(成功筛选出流量来源为二级或者三级的行数,并且只展示 ‘流量来源’, ‘来源明细’, ‘访客数’, ‘支付转化率’ 这几列):
当然可以用其他方式索引行,比如使用条件判断:
1 | df2.loc[df2['访客数']>df2['访客数'].mean(), :] |
一个条件判断不够,那你可以试试多个:
1 | df2.loc[(df2['访客数']>df2['访客数'].mean()) & (df2['流量来源'].isin(['二级', '三级'])), :] |
6. 数据合并
6.1 纵向合并
将几个数据纵向拼接起来,使用concat函数(需要总想数据维度完全一致)
1 | df = pd.concat([d1, d2, d3]) # 将数据d1,d2,d3纵向合并 |
输出结果:
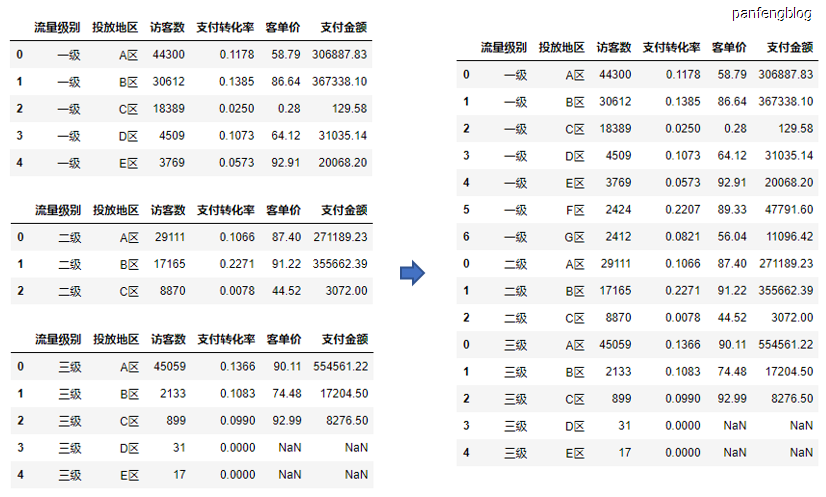
6.2 横向合并
使用merge函数(但是也可以使用concat,只需设置一下axis),merge函数可以允许横向维度不同的情况。
函数原型:
1 | merge(left, right, left_index, left_index, right_index, left_on, right_on, how) |
参数说明:
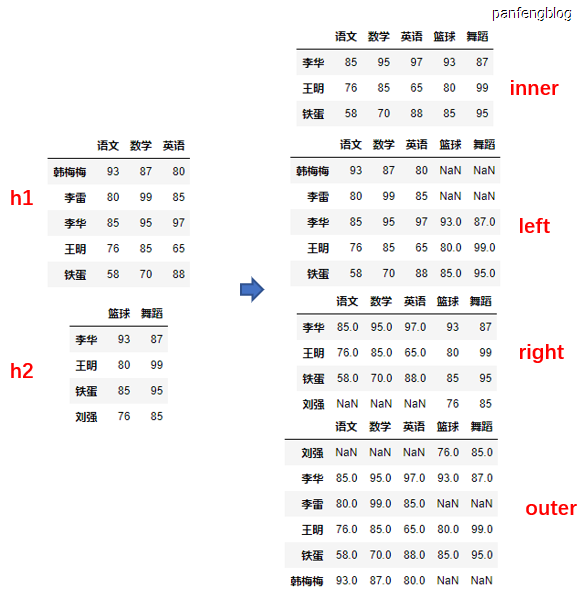
left:参与合并的左侧DataFrameright:参与合并的右侧DataFrameleft_index:bool类型,当为True时将左侧行索引作为连接的键right_index:bool类型,当为True时将右侧行索引作为连接的键left_on:左侧DataFrame用于连接键的列right_on:右侧DataFrame用于连接键的列how:连接方式,包括’inner’(连接键取交集), ‘outer’(连接键取并集), ‘left’(取左侧连接键), ‘right’(取右侧连接键)。(默认为inner)
栗子1:
1 | # 分别尝试不同的连接方式,并且都是使用索引作为连接键 |
运行后结果:
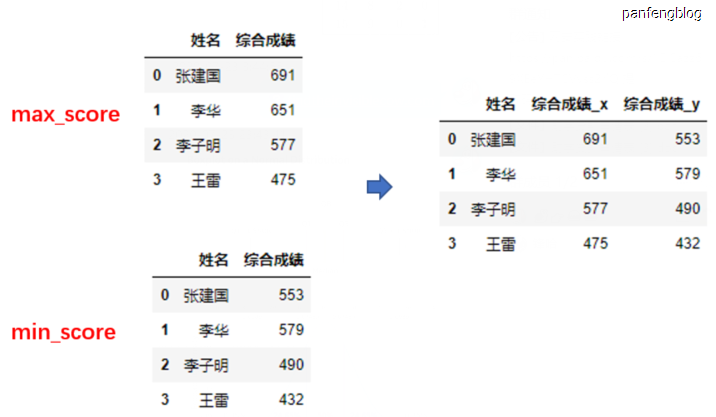
栗子2
1 | score_combine = pd.merge(left=max_score, right=min_score, left_on='姓名', right_on='姓名', how='inner') |
合并效果
7. 数据行的操作
7.1 删除空行
使用dropna可以去除含有缺失值的行
1 | df.dropna() # 删除表中含有缺失值的行 |
运行结果
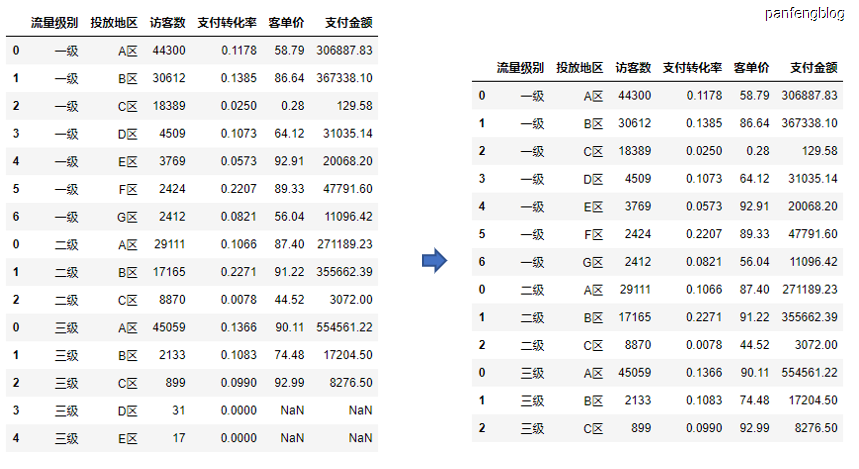
删除空行默认是删除含有缺失数据的行,当然也可以指定某列中的含有缺失数据的行。
1 | df.dropna(subset=['客单价']) # 当然也可以指定参数 |
7.2 行去重
将DataFrame中重复的行去掉(当然也可以指定列进行去重,设置subset=[]即可)
1 | repeat = pd.concat([df, df]) |
输出结果:
1 | 30 15 |
7.3 行排序
使用sort_values按照指定列进行排序,而且可以同时指定多列(现在第一个指定列的基础上,再进行后续排序)
1 | sort_df = df.sort_values(['流量级别', '支付金额'], ascending=False) |
输出结果
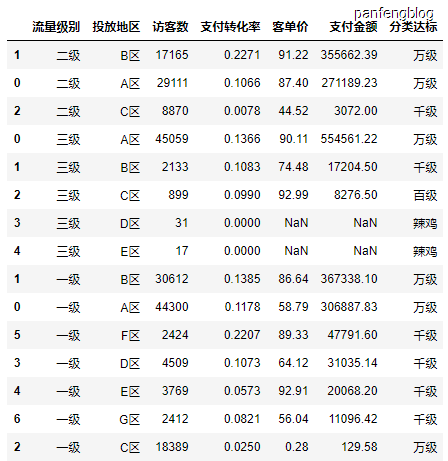
7.4 行分组
将数据按照某一列的值进行分组,然后再分组的基础上再进行其他操作(比如sum(), max(), min()等等)
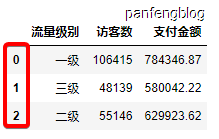
1 | df.groupby('流量级别').sum() # 按照流量级别分组后然后对各项数据进行求和,有的变量不是数值型变量无法求和 |
输出结果:
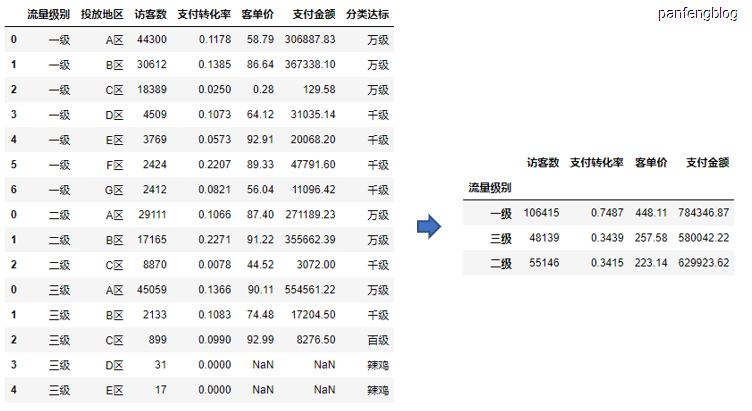
当然也可以指定数据项进行统计
1 | df.groupby('流量级别')[['访客数', '支付金额']].sum() # 选择指定的数据项进行统计 |
输出结果:
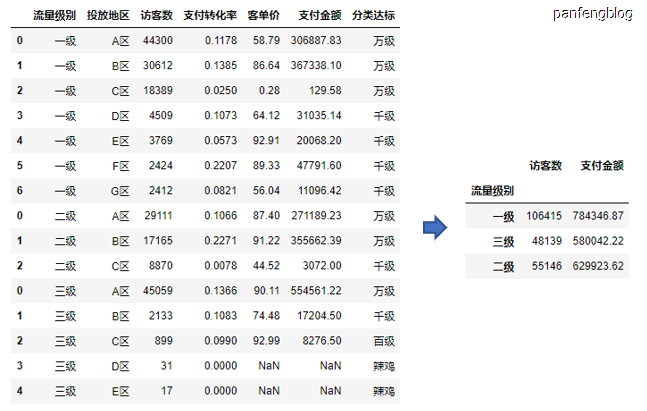
可以看到上述栗子分组后都会将分组项默认转化为index,当然我们可以指定参数,不让其成为index
1 | df.groupby('流量级别', as_index=False)[['访客数', '支付金额']].sum() # 分组后默认转化为索引列,当时可以指定 |
输出结果
7.5 行打标
往往行就是代表一个样本数据,我们经常就会有这样的需求,需要对样本进行打标,实现这一个打标的过程我们可以使用切分函数cut。
函数原型:
1 | pd.cut(x, bins, right, labels) |
参数说明:
x:待切分的一维数组bins:切分方式,① 传入列表,则会按照列表中各个数据所形成的区间进行切分;② 传入数字,则会将数据切分成指定组数。right:bool类型,True时为左开右闭,否则相反label:各个区间所对应的标签,也可不指定
我们一个一个逐步深入:
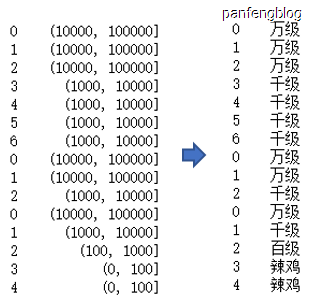
1 | pd.cut(x = df['访客数'], bins=[0, 100, 1000, 10000, 100000], right=True) |

进一步的,尝试给各个区间打上标签:
1 | pd.cut(x = df['访客数'], bins=[0, 100, 1000, 10000, 100000], |
输出结果
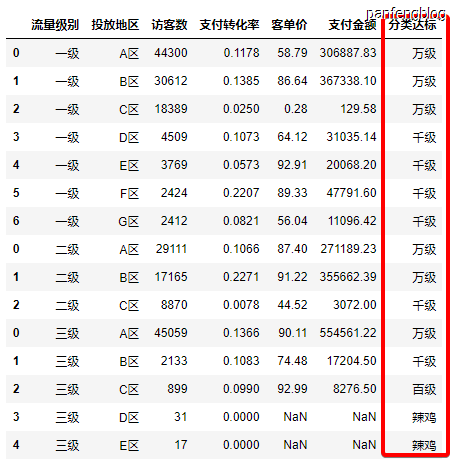
有了以上这些我们就可以给我们的DataFrame打标了
1 | df['分类达标']=pd.cut(x = df['访客数'], bins=[0, 100, 1000, 10000, 100000], |
输出结果:
8. apply函数
数据进行了行分组后就可以使用apply函数对各个组进行处理,可以使用现有的一些函数,如max,min等等,也可以自己定义,所以有时候就非常的方便。
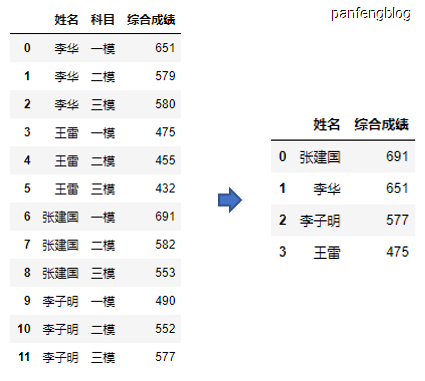
使用现有的一些函数:
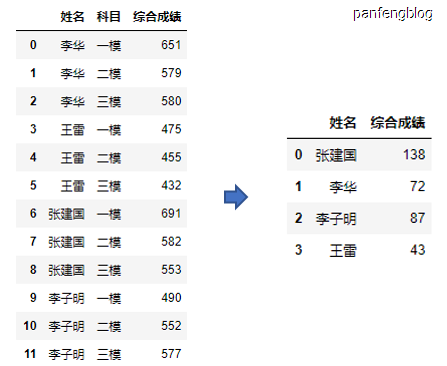
1 | max_score = score.groupby('姓名')['综合成绩'].apply(max).reset_index() |
输出结果:
自定义apply函数
1 | def bias(x): |
输出结果: