Faster-RCNN源码解析(simple-faster-rcnn-pytorch)
这里采用源码地址:点我
想了很多种方式详细解析Faster-rcnn的源码,但是Faster-rcnn源码比较复杂,有比较长,功能模块又非常多,一一介绍的话可能会看的晕头转向,所以我还是从预测和训练两个过程种用到的一些功能模块进行一些介绍,这是我个人阅读过程的理解(自己复盘的时候也能快速上手),当然能供大家参考就更好了,如有错误还望指正。
整体工作的流程图
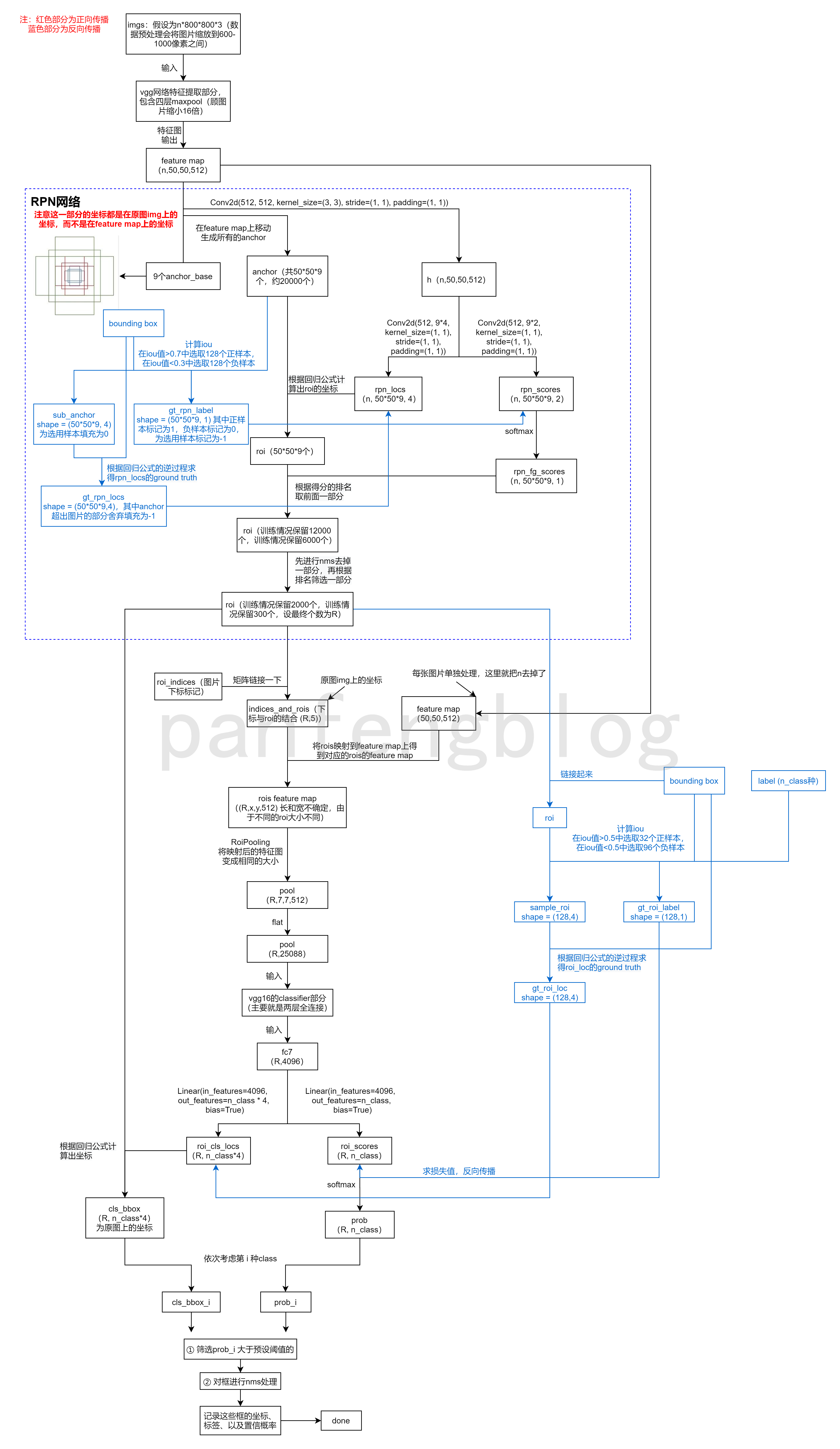
1 预测过程
1.1 vgg16网络结构
代码位置:./model/faster_rcnn_vgg16.py
1 | def decom_vgg16(): |
上述vgg16是直接加载的torchvision.models中现有的vgg16。
上面代码的vgg16分为两个部分,提取特征的feature部分和最后分类classifier部分:
- 对于提取特征的
feature部分,作者只采用了vgg16的原有特征部分的前30层(其实就是去掉了最后一层maxpool,所以整个网络只有四层maxpool),并且冻结了前十层; - 对于最后分类
classifier部分,作者根据需要选择是否删除其中的drop out层。
对于torchvision.models中自带的vgg16的网络结构在下面介绍:
我们首先直接看看原始feature和classifier的网络结构
加载feature和classifier
1 | from torchvision.models import vgg16 |
查看feature结构
1 | for i in range(len(features)): |
查看classifier结构:
1 | for i in range(len(classifier)): |
1.2 RPN网络结构
其中最重要的就是forward()方法,下面逐步进行介绍(假设卷积最后的输出的特征图为60*40*512,经过四次maxpool,即缩小了2^4=16倍):
- 将特征图的高和宽(
hh和ww)、slide window的滑动步长(默认设置为16,因为缩放了16倍,所以再特征图上移动一个像素点相当于在原图上移动16个像素点)以及anchor_base(就是那九个框)输入_enumerate_shifted_anchor()得到所有的anchor box。(如果按照stride = 16的话,最终将得到60*40*9=21600个anchor,注意:这些anchor是这个batch图片共有的) - 然后将特征图使用
3*3的卷积,保持通道数不变,此时输出为h。 - 将
h输入到self.loc网络中(用于定位anchor位置的全连接网络,其实是1*1的卷积,通道数变为n_anchor*4,对于每一个像素点来说就是全连接),然后再做了一些矩阵形状上的变化(具体形状太小可以参考下面代码注释),最后输出为rpn_locs,形状为shape = (n, hh*ww*n_anchor, 4) - 将
h输入到self.score网络中(用于求出anchor框的分类得分全连接网络,通道数变为n_anchor*2),最后输出为rpn_scores,形状为shape = (n, hh*ww*n_anchor, 2) - 将上述分类得分送入二分类的
softmax网络得到概率值(即为前景的概率,更通俗的就是框内有需要检测物体的概率),最后输出为rpn_fg_scores,形状为shape = (n, hh*ww*n_anchor) - 然后遍历这个batch的每一张图片,依次将其送入
proposal_layer()获取建议区域roi(请参看本文1.2.1),然后将相应的区域保存,并记录其下标(说明是第几张图片)。最后将所有的区域和下标整合得到rois和roi_indices
代码位置:./model/region_proposal_network.py
下面有RPN网络的完整代码(我做了一些个人理解的注释)
1 | class RegionProposalNetwork(nn.Module): |
1.2.1 获取建议区域
- 计算边框回归后的结果(请参看本文1.2.2),即调用
loc2bbox()函数,得到回归框roi(大约会有20000个) - 然后将
roi限制在图片范围内(即即将超出图片的部分裁剪掉) - 筛选过滤掉一些太小的框
- 然后将
rpn的得分矩阵socre排序,取分数的前n_pre_nums个(训练情况下为12000,测试情况下为2000) - 对剩下的
roi框进行nms处理(默认的nms阈值为0.7) - 最后再取剩下的
roi框的前n_post_nms个(训练情况下为6000,测试情况下为300)
下面是代码,做了一些个人理解的注释:
代码位置./model/utils/creator_tool.py
1 | class ProposalCreator: |
1.2.2 计算回归边框位置
其实就是根据以下回归公式,获取回归后目标框
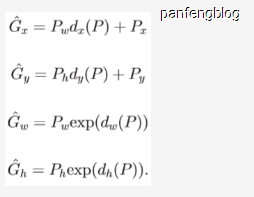
以下是代码,附带我的一些理解注释:
代码位置./model/utils/bbox_tools.py
1 | def loc2bbox(src_bbox, loc): #已知源bbox 和参数组loc(即偏移量和缩放量),求目标框G |
1.3 分类网络
由RPN网络已经得到了rois,接下来只需要对rois进行边框位置回归以及框内类别的回归了,分为以下几个步骤:
- 按照缩放比例,将rois映射到feature map上,然后进行RoiPooling,从而达到相同大小的特征输出,最后输出为pool,
shape = (R', 7, 7, 512)。 - 进行flat操作,pool,
shape = (R', 7*7*512) = (R', 25088) - 将pool送入坐标回归的全连接网络,输出为roi_cls_locs,
shape = (R', n_class*4) - 将pool送入类别回归的全连接网络,输出为roi_scores,
shape = (R', n_class)
这是这一一部分的源码(在我的理解上做了一些注释)
代码位置:./model/faster_rcnn_vgg16.py
1 | class VGG16RoIHead(nn.Module): |
1.4 得到最后结果
代码位置:./model/faster_rcnn.py 这里主要介绍的是_suppress()函数
下面是主要步骤:
- 将
roi_scores输入到softmax层中,得到prob置信概率(这部分代码在predict()函数中,以下描述都是在_suppress()函数中) - 然后对于第
l类的框cls_bbox_l以及相应的置信概率prob_l,首先对其筛选出prob_l大于阈值的,然后再对框进行nms处理,这样就得到了最后的结果,将相应的位置、标签以及置信概率记录下来即可
下面是代码(加了个人注释)
1 | class FasterRCNN(nn.Module): |
2 训练过程
2.1 RPN网络的训练
2.1.1 由目标框和源框获取偏移参数
其实就是1.2.2过程的逆过程,根据回归公式的逆过程得到偏移参数。
以下时代码部分(做了一些个人理解的注释)
代码位置./utils/bbox_tools.py
1 | def bbox2loc(src_bbox, dst_bbox): #已知源bbox 和目标框,求相应的参数组 就是loc2bbox的逆过程 |
2.1.2 获取ground truth
将人工标注的bounding box以及所有的anchor输入到bbox2loc()中就能得到偏移参数的ground truth,但是anchor中绝大多数样本都是负样本(即与bounding box相差很远),而正样本非常少,所以只筛选一部分正负样本。
- 计算bounding box与所有anchor的
iou值,在iou值大于0.7的样本中随机抽取128个正样本生成相应的标签(1) - 在
iou值小于0.3的样本中随机抽取128个负样本生成相应的标签(0) - 由此我们就获得了256个样本
sample_roi,并记录其标签gt_roi_label(表示前景或背景) - 然后将256个样本
sample_roi(源框)以及人工标注的bounding box(目标框)输入到bbox2loc()中就能得到偏移量的准确值gt_roi_loc
下面是代码部分(做了个人理解的注释)
代码位置:./utils/creator_tool.py
1 | class ProposalTargetCreator(object): # 挑出128个roi框并赋予groud truth(准确的位置参数和分类参数) |
2.1.3 计算损失值
RPN网络需要训练的部分就是位置修正参数和种类参数(前景和背景)的卷积网络。
对于位置修正参数,我们只需要根据人工标定的bounding box,然后结合生成的anchor box就能获得推得位置修正参数的ground truth(其实就是由anchor box和和位置修正参数推到ROI的逆过程),然后计算Smooth L1 Loss(探测边框回归)
对于种类参数,计算Softmax Loss(探测分类概率)
得到上述的两个损失值,然后根据下列的损失函数就能得到最终的损失函数:
代码部分(代码位置:./trainer.py):
1 | def _smooth_l1_loss(x, t, in_weight, sigma): |
2.2 最后预测网络的训练
2.2.1 获取ground truth
其实最后预测网络的训练和RPN网络的训练实质是相同的,因为也是一个位置偏移量和分类结果的训练,但是稍有不同:
- 由bounding box(目标框)和rois(源框)输入到
bbox2loc()中得到得到预测网络的准确值gt_roi_loc(同样需要筛选出一些正样本和负样本) - 由iou值获取相应的label(n_class+1中,多一种表示背景),即
gt_roi_label
然后相应的代码和上述RPN过程是一样的,之后损失值的计算也同样相同,所以在此不再赘述。