k-means算法原理分析与实践
原理分析
一些说明
假定样本集$D=\left\{x_1,x_2,···,x_m\right\}$包含m个无标记样本,每个样本$x_i=(x_{i1},x_{i2},···,x_{in})$是一个n维特征向量,聚类算法将样本集划分为k个不相交的簇$\left\{C_l|l=1,2,3,..,k\right\}$表示,用$\lambda_j\in\left\{ 1,2,…,k \right\}$表示样本$x_j$的簇标记,即$x_j\in C_{\lambda_j}$,所以最终聚类的结果可以用包含m个元素的簇标记向量$\lambda = (\lambda_1,\lambda_2,…,\lambda_j)$表示。
K均值算法
给定样本集$D=\left\{x_1,x_2,···,x_m\right\}$,k均值算法对于一个簇划分$C=\left\{ C_1,C_2,…,C_k \right\}$的最小化平方误差为:
$E=\sum_{i=1}^{k}\sum_{x\in C_i }^{} ||x-\mu_i ||_{2}^{2}$ 其中 $\mu_i = \frac{1}{C_i}\sum_{x\in C_i }^{} x$为簇$C_i$的均值向量。($||.||_2$为L2范数,Lp范数:向量各个元素绝对值的p次方求和然后求1/p次方)
直观来看的话,$E$就是刻画了簇内样本围绕簇均值向量的紧密程度,$E$值越小,簇内样本相似度就越高,这也就是k均值算法需要达到的最终目的。
下面是k均值算法的伪码表示:

算法实践
使用的是Iris数据集(鸢尾花卉数据集),是一类多重变量分析的数据集。数据集包含150个数据样本,分为3类,每类50个数据,每个数据包含4个属性,分别是花萼长度,花萼宽度,花瓣长度,花瓣宽度。使用k-means聚类算法对数据进行聚类。
需要整个工程文件(包含数据集)可以点击这里
导入python库
版本说明:
matplotlib:2.2.3numpy:1.15.4sklearn:0.19.2
1 | import numpy as np |
加载数据
输入文件名即可,返回一个原始数据的numpy矩阵(维数为150x5,每个增加了一个属性用于存储花的种类)和一个存储颜色的矩阵,用于查看初始数据时画图。
1 | def load_dataset(filename): |
1 | iris_data, color = load_dataset('iris.data') |
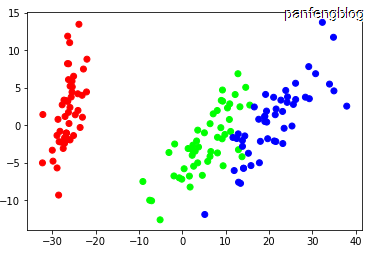
查看初始数据
使用pca将四维数据降至二维,直观查看数据分布:
1 | irisPca = PCA(n_components=2) # 使用PCA降维便于直观查看初始数据 |
输出结果:
K-means算法
1.随机选取初始向量
这里随机选取了数据的1,2,3个(可随意选取)
1 | u1 = iris_data[0][1:] |
2.开始循环
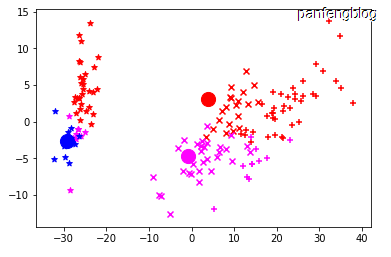
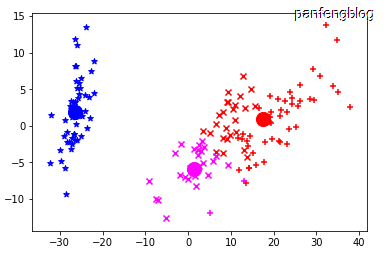
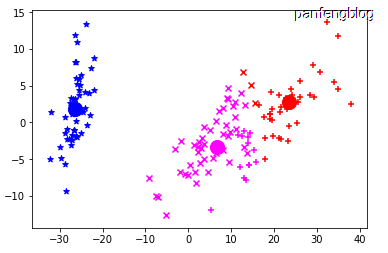
已经选取了初始向量,接下来只需要不断重复:1.将数据根据最近距离划分到相应的簇;2.更新均值向量(在原理分析部分已经说过)。并且在每个循环中,都画出了该轮循环后的一个聚类的状态。(为了能将高维数据直观表示,这里使用了前文训练好的pca降维,不同的颜色代表不同的簇 三种花分别用’*’,’x’和’+’表示,均值向量点用圆点表示)
1 | while True: |
输出结果(这里只截取了一部分输出结果):
刚开时循环:
循环几轮后:
最终聚类结果:
需要完整代码可以点击这里。